Simulating an equity strategy is difficult. Much more so than simulating a futures strategy. There’s a lot more moving parts to care about. Much more complexity. All too often, I see articles and books that just skipped the difficult parts. Either they didn’t understand it, or they hoped it wouldn’t matter. It does.
When I set out to write Stocks on the Move, I wanted to make sure that anything I write about could be replicated by readers. There’s nothing worse than books that show stellar simulation results, only to be vague about how it’s done. Even worse, the books that asks you to buy some trading system for thousands of dollars to find out how the results in the book were made. I wanted to show all the details, just like I did for Following the Trend.
But showing all the details isn’t enough. There’s still the issue of cost. In the hedge fund space, we’re lucky enough to play with quite decent budgets. We can spend quite a bit of money on market data, applications and developers to make sure we get what we need. That’s not a luxury that most readers will have. So I have to find a way to get the strategy for the book done on the cheap.
I spent some time researching how to get the desired quality at a reasonable price. It was an interesting task, and hopefully my findings can help you improve your own simulation quality.
The Task
Stocks on the Move is about systematic equity momentum. The strategy picks the highest momentum stocks, constructs a portfolio and uses periodical rebalancing to ensure that we have the right stocks at the right weights. Simple concept, tricky implementation.
I decided from the start to use the S&P 500 stocks as investment universe. It’s simply easiest for a book targeted at hobby traders. US large caps is something everyone can trade. Trading costs are low. It’s a single currency index. It seemed like a reasonable choice to limit the book to this one index.
And finding data for US large caps is easy. Right?
Find Data

What now?
Finding data isn’t easy. Forget about all the free data sources you were just thinking of. None are good enough for simulations. Let’s take look at our minimum requirements.
- Daily or higher frequency prices.
- Coverage of all current S&P 500 constituents.
- Coverage of all previous S&P 500 constituents.
- Coverage of graveyard, i.e. all delisted former members of the S&P 500.
- S&P 500 historical joiners and leavers table.
- Mapping of changed symbols, e.g. mergers, spin-offs etc.
- Corporate actions adjustment factors.
- Cash dividends adjustment factors.
That got a little more complicated than you had expected, didn’t it? Trust me, you need this.
A key point is that you have to make sure your simulation only looks at stocks that were part of the index on a given day. If you were to use the current index members and run a ten year back test on that, it would of course look great. It would also be utterly useless.
The stocks in the index right now are there for one reason only. They had great historical performance, and therefore they became valuable enough to be included in the index. To think that you would have traded the same stocks ten years ago is ridiculous. It would be reasonable however to include only members of an index, as it looked at that date.
For that we need to know when stocks joined and left the index. Many of those stocks are now delisted or merged or otherwise not present in the same shape as before. This adds complication.
Another vital point is about cash dividends. While most data providers already adjust prices for corporate actions, such as splits, they normally don’t adjust for cash dividends, nor do they provide factor data for it. Cash dividends has a massive impact over time, and ignoring it is not an option.
So, how do we find all this data at reasonable price?
I investigated a few different solutions, and in the end I went with a company called QuantQuote, which I had never heard of before. I know your next question. Do I get paid for marketing QuantQuote? Is this article really just a thinly veiled plot to siphon off your hard earned cash?
Sadly no. I asked them if they were interested in a similar deal that I have with CSI, where my readers get a discount and I get a kickback. I mean, a referral fee… They didn’t seem too interested. Well, I don’t base my recommendations on who pays me, I base them on what I like. And QuantQuote got the job done. I believe I paid around $1,000 for an initial historical data dump at minute resolution, and then $100 per month for updates. Given the quality and coverage, I believe that to be quite reasonable.
Structuring the Data
Delivery format vary between data providers. QuantQuote delivers flat files of three types via FTP. There are raw data files, factor files and mapping files. It’s up to you to organize this data in a way that you can use it for your purposes.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
20151006,1005,17.1,17.1,17.05,17.06,15255,1,0,0,123 20151006,1006,17.06,17.06,17.03,17.03,155937,1,0,0,123 20151006,1007,17.03,17.06,17.0228,17.03,83340,1,0,0,123 20151006,1008,17.03,17.065,17.03,17.06,36996,1,0,0,123 20151006,1009,17.07,17.1,17.07,17.098,6776,1,0,0,123 20151006,1010,17.095,17.12,17.09,17.105,42269,1,0,0,123 20151006,1011,17.09,17.11,17.09,17.09,19429,1,0,0,123 20151006,1012,17.095,17.11,17.07,17.075,31076,1,0,0,123 20151006,1013,17.075,17.11,17.075,17.11,15139,1,0,0,123 20151006,1014,17.115,17.125,17.105,17.1199,39654,1,0,0,123 20151006,1015,17.12,17.12,17.09,17.1,25568,1,0,0,123 20151006,1016,17.105,17.12,17.105,17.11,7987,1,0,0,123 20151006,1017,17.12,17.12,17.09,17.095,26566,1,0,0,123 |
The data file above shows the default layout, at minute resolution. One of these files is delivered on the FTP server every day for every stock. Now, this is raw data of course. We need to apply adjustment factors to get real prices.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
19980102,0.9351001,0.0357143 20000620,0.9351001,0.0357143 20050225,0.9351001,0.0714286 20120808,0.9351001,0.142857 20121106,0.9391149,0.142857 20130206,0.9434046,0.142857 20130508,0.9489036,0.142857 20130807,0.9551862,0.142857 20131105,0.9614936,0.142857 20140205,0.9671058,0.142857 20140507,0.9728944,0.142857 20140606,0.9783283,0.142857 20140806,0.9783283,1 20141105,0.9831946,1 20150204,0.9874581,1 20150506,0.9913555,1 20150805,0.9954939,1 20501231,1.0000000,1 |
The above table shows the adjustment factors for Apple. The first field is for dividend adjustment, the second is the split factor. If the raw price in the data file is multiplied with the split factor, you get what you would normally see in most charts. Multiply by the dividend factor as well, and you get a total return series.
|
1 2 |
20001229,cmb 20501231,jpm |
The mapping table lets us link changed symbols, merged companies etc. The example above is for the JPM mapping file, where it CMB became JPM in 2001.
Are you with me so far? Good.
All your database are belong to us
Since I never had much trust for flat files, a better storage is needed. I’m not really in the mood for making a data adapter to the simulation software that traverses hundreds of zip files, each with hundreds of flat files inside. No, we need to automate this whole thing and get some structure going.
Since the files are delivered on an FTP server, the first thing you need to do is automate a download. No, no, I’m not going to show you code for that. That’s what StackOverflow.com is for. It’s easy, trust me.
Putting everything into a real database makes a lot of sense. In a database, you’ll have much greater flexibility and speed when you want to access the data. My preferred database solution is MySql. It’s free, it’s fast, it can do everything you need. I’m not going to give you arguments for choosing MySql over MS SQL or similar. It really doesn’t matter. If you like another database, fine, go with that.
Now of course you have to figure out what you might need in your database, and how to structure it. Do you really need to learn about databases and all these technical things just to make a little equity simulations? Yes, you really do. If you want to make a simulation that’s not a complete waste of time, you really do.
If you want to play in the kiddie league, get some cheap retail technical analysis software and load it up with data from Yahoo Finance. It might be fun, but don’t expect anything actually useful to come out of it. This article is for those who are ready to put in some work to get things right. If you want to be a professional, be a professional. Put in the work needed to learn and get it right, or you’ll never be able to play in the big boy league.
Back to the structure. You’ll likely need at least four tables for this exercise. First, let’s make a table with raw price history. I’ll simplify it slightly and make it a daily resolution table, since this article probably lost most readers already due to the complexity. Here’s an example of how your equity_history table could look like.
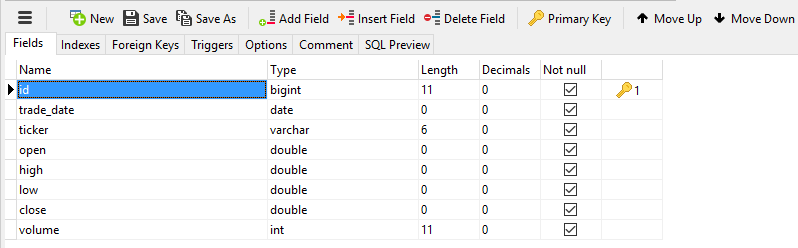
Table design example for equity_history
Got it? Good, then we’ll make one more table for the factors, and one for the mappings.
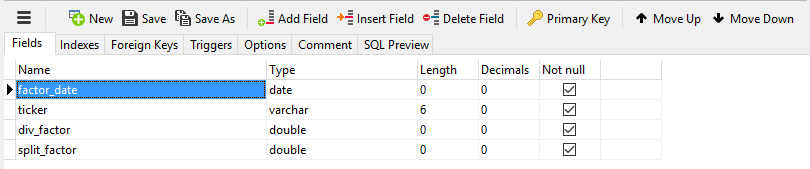
Table factors

Table mapping
There. Now we have what we need to get proper historical data. You just need to ask these three tables politely, and they’ll return a really nice properly adjusted and mapped data series to you. What, it’s not clear already? Fine, I’ll show you a sample SQL query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
SELECT h.trade_Date, OPEN, high, low, CLOSE, volume, IFNULL( ( SELECT div_factor FROM ( SELECT factor_date, ticker, div_factor, split_factor FROM factors WHERE ticker = 'aapl' ) x WHERE h.trade_date <= factor_date LIMIT 1 ), 1) AS divFactor, IFNULL( ( SELECT split_factor FROM ( SELECT factor_date, ticker, div_factor, split_factor FROM factors WHERE ticker = 'aapl' ) y WHERE h.trade_date <= factor_date LIMIT 1 ), 1) AS splitFactor FROM equity_history_daily h LEFT JOIN ( SELECT dates.trade_date, ( SELECT map_to FROM ( SELECT map_date, map_to FROM mapping WHERE map_from = 'aapl' ) map WHERE dates.trade_date <= map_date LIMIT 1 ) AS localTicker FROM ( SELECT DISTINCT trade_Date FROM equity_history_daily where trade_date >= (select min(map_date) from mapping where map_from = 'aapl') ) dates ) tickers ON h.ticker = tickers.localTicker AND h.trade_date = tickers.trade_date WHERE localTicker IS NOT NULL |
Yes, yes. I know this query could be made prettier and shorter. I wrote it this way in hope that it would be easier to read and follow. End result is the same.
And what will this little query give us?
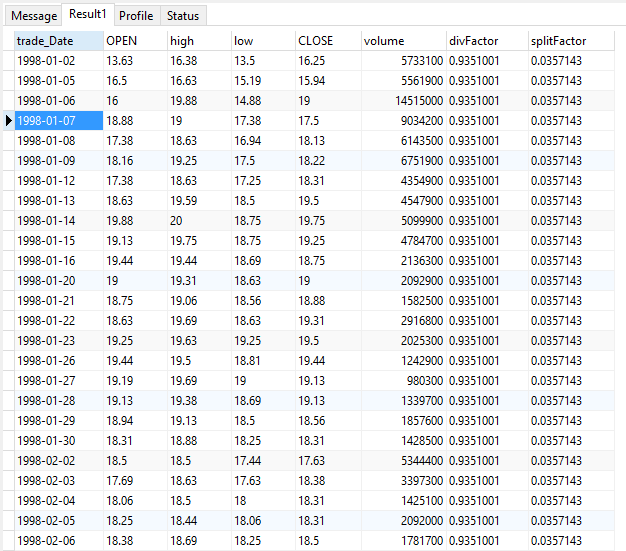
A brief history of Apple
But the price are still not adjusted, right? That’s correct. This query is designed to give you the all the info, in case you’d like access to unadjusted data or data only adjusted for splits for some reason. Don’t worry, from here it’s quite easy. If you multiply all the price data by the split factor, you get what you’d normally see in stock charts. That is, prices adjusted for splits and corporate actions. If you also multiply by the dividend factor, you’ll get a total return series. Easy, isn’t it? Oh, and of course, you’d need to divide the volume by the split factor in case you’re using the volume field for anything.
Are we there yet?
Not quite. We’ve only got the proper data and pushed it into a database. All we’ve done is to create a decent data structure. There’s a lot more to go. To see how this exciting story plays out, tune in for the next episode.
I was planning on writing a single article about how to make proper equity simulations. Somewhere along the ride though, I realized that it would be a far too long article. In fact, I’m not sure if anyone is still reading at this point.
You’re still there, right guys? Right? Guys..?

Ok then.
In that case, I’ll take this opportunity to shamelessly plug our really neat subscriber services. Yes, we’ve got those here. There’s a unique futures analytics package, which gives you access to pro level data and information on global futures. The price for this was recently lowered, plus the new equity package is included as well. Or you can get the equity package alone, with momentum analytics access for the US large cap markets for a bargain.
Fine, I’m done.




Hi Andreas,
Again, another excellent article which guids me into the dark. Very helpfull!
You only outlined the composition of the index. How do you handle this issue? Another table into the datebase?
I look forward to read PART 2. In the meantime I enjoy some literature about mySQL. 😉
Regards,
Sebastian
Oh, that’s right. I should have covered that in this article too. Well, I’ll do it in next post.
Yes, it’s another table and I query it directly from the simulation software. I’ll cover that in the next article.
I started out writing a single article about making equity simulations, but I realized half way through that it would get far too long.
MySql is very easy to use. I prefer to use NaviCat Premium to work with the database, but you can do the same things with free tools.
But surely, after the book showing us the results we don’t need to backtest the strategy? 😉
You should always question and verify everything. Do the math, check the details, form your own opinions.
Unless of course the information comes from me, in which case it is per definition the truth and should be universally recognized as such.
Of course I was baiting you Andreas! 🙂 You are very correct though. I was reading a magazine over the weekend that implied a momentum strategy using OEIC/UTs and buying the best performing (in % terms) fund over past 6 months, holding and then repeating process would have yielded stellar results. I did some quick modelling based on past quarters % performance from 2008 lows and it yielded a very different result – a catastrophic loss in fact! So, the devil is obviously in the criteria selection details that they chose to omit. I would imagine they tested a reliable, large AUM, low volatility data set maybe? But it shows the power of always testing theories instead of taking somebody’s word for it!.
Great article as always, Andreas!
Getting good data including all the historical constituents must indeed make all the difference; garbage in, garbage out.
I was wondering though, what do you think about much lower resolution, let’s say monthly data and not even for all the constituents, but simply for whole index or individual sectors – such data must be much cheaper. Do you think, for example, that even historical monthly SPY data on finance.yahoo.com are still bad?
And then, how can you tell if a data-source provider is good or bad quality? I mean, what do you compare it with? I understand just meeting your requirements you listed in the article is one way, but talking about monthly ETF data, do you basically have to believe the provider or is there some “verification” one can make?
ETF data is generally easier. You normally don’t have either dividends or splits to care about, so there’s not that much that can go wrong.
Of course, always look into an ETF carefully before buying it. Many ETFs are not at all what they sound like. As I’ve written about before, a large number of ETFs are just structured derivatives, packaged, relabeled and sold to people who don’t know what structured derivs are.
Does Yahoo Finance adjust prices for cash dividends? Thanks
I think they have that data, but they lack things like delisted stocks, historical constituents etc.
Do you get a separate files with only split and dividends factors from QuantQuote? I have historical data from them and there’s only one file per stock. Thank you.
Yes, the factor files and mapping files come separately. The stock files are unadjusted.
This is fantastic. I really mean it. It’s very hard to learn this kind of practitioner stuff unless a practitioner lays it out for you — when it suddenly becomes easy. Glad to have found this blog.
In your search for a data provider did you stumble across anything for the FTSE indexes? Finding a reliable data source for the FTSE All Share constituents is proving to be like finding a needle in a haystack.
I’ve even considered reconstructing the indexes bases on the quarterly ‘events’ on the LSE website but that will only work for FTSE100 which is too small a base.
I didn’t, mostly for the reason that I didn’t look for it. I actually don’t like trading UK stocks very much. The obvious issue is the stamp duty. Who wants to pay fifty points for a trade? How much better would a stock be to justify that?
Then of course, UK stocks have severely underperformed the rest of Europe for years. The FTSE has been a train wreck of an index year after year. There has been very little reason to buy stocks in London.
Sooner or later performance will come back in the UK. I guess. But it can take time. Even if it manages to perform on par with the continent, stamp duties will still make them less attractive.
Hi, Andreas,
In your book you recommend to write our own code to simulate the momentum strategy with reliable data. By looking at how you paid the data, it seems to me the above task is unnecessary unless a) you no longer provide subscription service, or b) trading in another Market.
so question 2:
Have you run the strategy against another stock market?
thanks,
Yes, it works fine in the markets where I’ve tried it. Just be aware that you may have problems if you use a very narrow index and that you’ll have an additional FX overlay problem if you use a mixed currency index.
Excellent book.
I can get a linear regression line on stock charts. I there any way to get R2 other than computing the value for each stock on excel?
Hi Blair,
Linear regression slope isn’t very useful, as it can’t be compared across stocks of different prices.
Depending on what charting software you have, you might be able to make your own indicator. The math is quite simple and it should be possible in any decent charting software.
I also publish daily updated analytics and portfolio reports here on this site, in the premium section: http://www.followingthetrend.com/equity-momentum-report/
Hi Andreas,
Great article, as always, but what is you opinion on using a site that offers such data (do they really meet all your criteria?) and a platform to model one’s strategy for free, such as Quantopian? I am of course not promoting it, nor am I associated with the company in any way, but I must admit I have been using it. What would be the pros and cons in your opinion?
With most free data sources, you get what you pay for.
Quantopian however seems to be quite high quality and their simulation engine looks pretty good too. It would be unfair to compare it to high end desktop quant modelling tools, but it seems like a very good alternative. It’s free and it works. Setting up something similar on the desktop takes some programming knowledge and time.
Of course, Quantopian are flying me to NY in a month to speak at their QuantCon event, so perhaps I’m not the most unbiased guy at the moment…
Great article Andreas,
How would one deal with mergers and acquisitions of stocks, either on SQL, or RightEdge?
It all depends on how your data provider structures the data. QuantQuote for instance will give you everything, and leave the implementation to you. They’ll give you all the actual tickers as they looked at the time and then mapping tables for you to stitch it together. I load it all into a MySql and write a complex query to get the ready, fully adjusted data set.
Andreas et. al.
Have you had any experience with QuoteMedia data provided through Quandl? I have taken a look at QuantQuote, and the data is good. However, the “cheap” data is only available for S&P 500, the full set is a bit too much for a hobbyist. So I have explored Quandl. For EOD data, the QuoteMedia price is reasonable. On top of this, Quandl API is way ahead of other data providers. Thoughts? – thanks.
I haven’t tried QuoteMedia. I do use QuantQuote and the quality is good.
I’ve been testing Norgate for a while now as well. At first I was a little skeptical about them due to their very low price point, but to my surprise the quality seems very good. In fact, I’m in the process of migrating much of my models to Norgate data at the moment. They just released a great RightEdge plugin as well, which I’ve been helping them with. It will simplify a lot of things, like historical index membership and such.
Try it out here: http://www.premiumdata.net/ref/ac.php
What price should I expect from QuoteMedia? I’m looking for EOD, delayed, on major exchanges. Thank you.
Hi Andreas, I looked at Norgate as well, but it seems like there data doesn’t have dividends info. There is an “alpha” version which does, but it only works with AmiBroker. Did I miss something from Norgate?
I’ve only used Norgate’s RightEdge plugin, and that certainly does adjust for dividends. It doesn’t provide dividends as a separate field, but it gives you the option of retrieving total return series, where the divs are included.
Just a quick note, we have added the ability for our “fast ring” testers to incorporate dividends into their trading systems.
Either they can adjust the price data so that all distributions/dividends are incorporated into the price data or track it as a separate indicator and “inject” the value of the dividend of the dividend into their simulation/trading account. Stops can also be adjusted according to these dividends too, so that you aren’t stopped out just because a distribution/dividend occurs.
Hi Andreas,
Is it possible data and there seems to be a problem with your data on some symbols? I may be wrong in which case, please correct me.
But I was doing some calculations to measure the adjusted slope to see if I got the same values as you. In the case of FCX I did. But in the case of MUR I got a different value. Now I checked your data and compared it with yahoo data and here is the issue.
For MUR there was a dividend on Feb 10th of .35 cents. You adjusted this price, but the prior prices Feb 9th and before were not adjusted to reflect this. Yahoo Data has different values than you for Feb 9th and before since they adjust the data before Dividend date.
However in FCX you did not do the same thing that you did with MUR. When there was a dividend on OCt 12, 2015 you adjusted all dates prior to reflect that. Here Yahoo data is the same as your data.
Why did you do it for FCX and not for MUR?
Is there an error or is it something I’m missing, in which case I’d appreciate if you please clarify.
Thank you.
Hi Jason,
I’ll forward your question to the data provider and see if they have a good explanation.
Andreas
Thanks Andreas.
I’d like to hear the answer.
Andreas in your book stocks on the move, you mention it might be useful to simulations on mid cap and small cap indexes as they may even yield greater return (and possible greater volatility).
if you were doing the stocks on the move equity model for mid cap or for small caps in Canada, could you tell me which indexes you would select? Also when comparing them to the index, buying when the index is above the 200 Moving Average, again which index? Or would you use the 200MA of S&P 500 for evaluating when to buy more stocks and when not to buy.
Would you know where to get the data for this index in the Canadian Sector.
I live in Canada which is why I’m asking.
Thank you.
Do you know which index you would compare
You’ll need a sufficiently broad index for the principles of the strategy to work. As long as you have at least a few hundred members and it’s not a sector specific index, you should be fine.
Use the same index for measuring the market trend.
The MSCI set of indexes are quite useful for these sort of things, though also quite expensive.
Andreas,
I was looking how you set your database up. Am I right by saying you have a table called “equity_history” for all the stocks you choose to put in it ? In other words, you don’t have a table for each separate stock correct? I was just confused on how to throw in the Ticker symbol on each line while I am putting in the date, close, high, low, open, and volume. I am also confused on how to update the table if all the stocks are in one table without it looking like a cluster of information all over the place. Any advice would be greatly appreciated. Thanks.
Hi Tim,
This is just basic database stuff, really. Having one table per symbol would indeed be extremely messy. Just put them all in the same table and make a unique index based on date and ticker.
A database table isn’t made for visual inspection. It’s not an Excel table. When you want something from the table, you ask for the info you need. Ask it to display all data for a single stock for instance, or all stock prices for a single date or whatever you want.
There’s no impact at all on how you would update the table.
I understand that database logic can be a little daunting if you’ve never been exposed to it, but this is really not difficult stuff. Install MySql locally, put some data in there and play around with it. It’s probably the best way to learn.
Hi Andreas,
This may not be the best place to ask this, but I’m hoping you could answer me anyway.
In your Clenow 30 day plunger model, I’m trying to emulate it but haven’t got the signals exactly timed to when you do.
When the trend is positive you buy on a dip of 3ATR’s from the high.
Do you calculate based on the Highest High in the last 20 bars, or the highest Close?
Small detail but could make a big difference in the model.
Thanks you.
Hi Jason,
I’ve sent you a direct mail with all the details.
Andreas
Thank you very much Andreas! I got the answer I was seeking.
One more question…
On the Core Trend Model with 50 day breakout, do you use an ATR of 100 or 20 for exiting position?
Reason I ask, with soybeans I see the same as you. I get an entry on Mar30th. However you are still in position, and I saw signal to exit on April 25th based on a dip of more than 3ATR using ATR(100)
In your book I thought it was ATR(100) we use but now I’m not sure.
Your soybean position is still open. I then changed my Exit ATR, to ATR(50) and ATR(20) and it was only the ATR(20) that would still have me in position and not have closed out on the dip of April 25th.
Is the model you currently use, set for Exiting position with an ATR(20) or ATR(100)?
Appreciate you taking the time to respond Andreas.
Thank you.