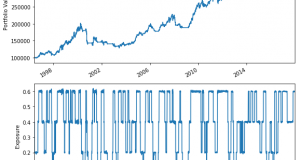
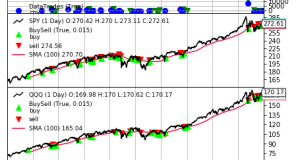
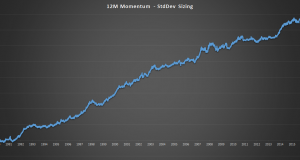
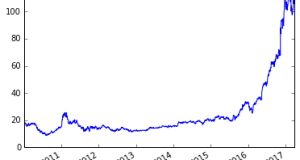
Complex Backtesting in Python – Part II – Zipline Data Bundles Posted by: Andreas Clenow in Premium July 20, 2018 1 Comment 34,582 Views Please Login to view this content. (Not a member? Join Today!) coding equities python quant simulation Tools Tutorials 2018-07-20 Andreas Clenow tweet